
Why the new Salesforce MCP isn't ready for GTM Engineers and RevOps.
An exploration of the official Salesforce MCP for GTM Engineering use cases.

A month ago I wrote that I’d fallen back in love with Salesforce. Salesforce didn’t change anything to make me feel that way. I simply realized I stopped having to click through the UI to use it– since I could have AI agents do the work for me. Thanks to Claude, I can create opps from email threads, auto-qualify inbound leads, backfill custom objects, and even enrich 100k+ records. And all because of the rich API surface Salesforce has quietly maintained (really, really well) for 25+ years.
That post hit a nerve. I got several GTM operators messaging me to ask how the plumbing actually works. The answer is the Model Context Protocol (MCP), the thing that lets an agent like Claude talk to Salesforce in natural language. And the next question was: How do I get that? This is where I’d point them to (surprisingly) an open source project that I was using…
That question got a lot more interesting last week.
What Salesforce announced, and when
There are two timelines running in parallel here, and it’s worth pulling them apart.

December 2024: A solo developer, Tushar (github: tsmztech), publishes mcp-server-salesforce (https://github.com/tsmztech/mcp-server-salesforce) under an open source/MIT license. It supports 18 tools. It does almost everything a GTM operator would want. You can query records, create them, update them, describe objects, run SOSL, execute anonymous Apex, and manage schema. I’ve been using it to build custom objects, populate data, set up workflows, and keep my CRM up to date automatically from emails/call transcripts (thanks to the Upside MCP).
May 30, 2025: Salesforce releases its own official DX MCP Server (https://github.com/salesforcecli/mcp), published as @salesforce/mcp on npm, in Developer Preview. They pitched at developers building in VS Code, Cursor, and Claude Code.
April 15, 2026 (five days ago): At TDX 2026, Salesforce announces Headless 360 (https://www.salesforce.com/news/stories/salesforce-headless-360-announcement/). The framing is key: “No browser required.” “The most ambitious architectural transformation in our 27-year history.” More than 100 new MCP tools and skills. The entire platform, reframed as infrastructure for AI agents. I turned into the heart-eyes emoji, immediately.
That’s the announcement I want to talk about. Because for a GTM audience, the messaging sounded exactly like what I wanted (and was already doing). AI does the CRM work, now with much better tools (yay).
What actually shipped

I pulled the full tool inventory of @salesforce/mcp directly from the repo. There are a LOT. Things like data, metadata, testing, code-analysis, orgs, users, aura-experts, lwc-experts, mobile, mobile-core, devops, enrichment, scale-products, experts-validation, etc (over 90 in total).
Here’s what the official server can do:
Run SOQL queries (but sadly, read only?!)
Deploy and retrieve metadata between your local DX project and the org
Run Apex tests and Agentforce agent tests
Run the Salesforce Code Analyzer
Scaffold LWC components, Aura migrations, mobile capabilities
List orgs, assign permission sets, create scratch orgs
Here’s what it cannot do:
Create, update, delete, or upsert a single record. There is no DML tool anywhere in the package.
Describe an object or retrieve picklist values. No schema introspection. If you have picklists, this is a blocker.
Run SOSL or cross-object search.
Execute anonymous Apex for one-off operations.
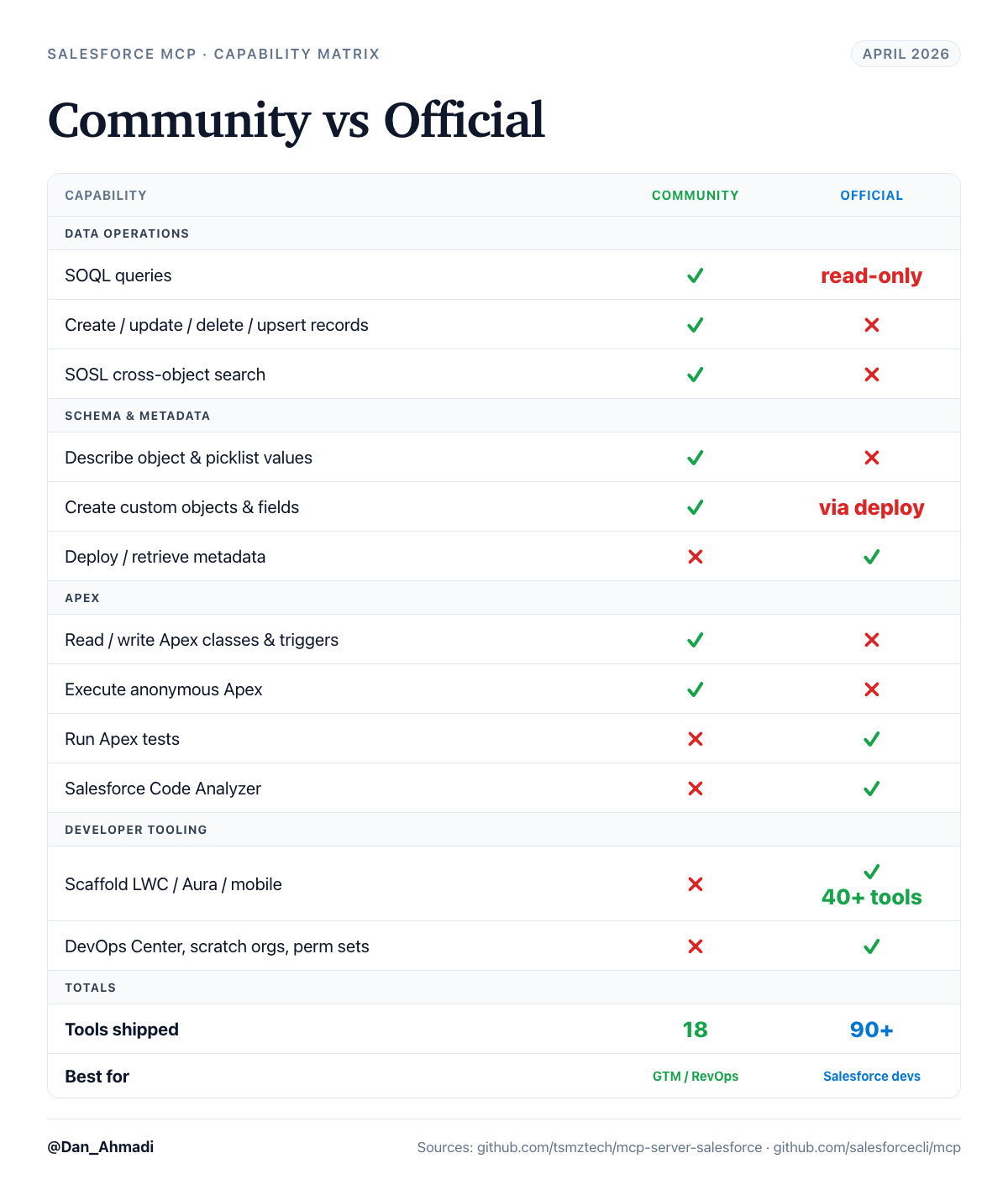
Turns out… every single thing I was doing in a GTM Engineer capacity (creating opps from emails, updating stages, enriching records, backfilling custom objects) requires at least one of those four capabilities. The official server cannot do any of them.
This is not a beta gap that will close soon– I believe it’s actually a design choice. The Salesforce DX team’s model is that your local DX project is the source of truth, and agents should deploy versioned metadata and run tests. Ad-hoc data mutation belongs elsewhere. That’s a defensible engineering stance, and may be appropriate for large organizations with swaths of SFDC devs. But it means the official server is a developer SDK, not a GTM Engineer/operator tool, despite the marketing framing.
The community MCP ships all four of those capabilities and it’s what I (continue to) run.
Security
A reasonable question: is one of these safer than the other?
In practice, for how most people will run them, no. Both use the local Salesforce CLI (sf) to authenticate. The same access token, org scoping, and user permissions. Whatever the authenticated user can do in the org, the MCP can do.
One nuance: the community MCP also supports username/password and OAuth client-credentials as alternative auth paths. Those could be riskier if you store credentials in a config file. Sidenote- please make sure your SFDC org is secured by Okta or similar– it’s worth the effort to keep things secure. The official MCP only supports CLI auth, which is slightly safer by default. If you use the CLI path for both (which you should), the security posture is identical.
“But isn’t the official one safer for a big org?”
This comes up every time I talk to a RevOps leader about this. The argument goes: the official MCP can’t write data, so it can’t cause damage. Hand it to anyone and the worst they can do is a bad query. Isn’t that the right choice for an enterprise?
Turns out that’s a reasonable assumption to make, but it’s not necessarily true.
Salesforce’s permission model already handles this. Whichever MCP you run, it authenticates as a specific user and inherits that user’s permissions. If your analyst can’t delete opportunities in the UI, they can’t delete them through any MCP either. The safety layer is the profile, not the tool. If your admin is worried about blast radius, the answer is a scoped service user with a tight permission set, not a server that happens to ship without DML.
The read-only property of the official server isn’t a safety feature. The DX team didn’t remove DML to protect you. They removed it because their model of the world is “mutate Salesforce through versioned metadata deploys, not ad-hoc data changes.” It’s their philosophy, not a designed guardrail.
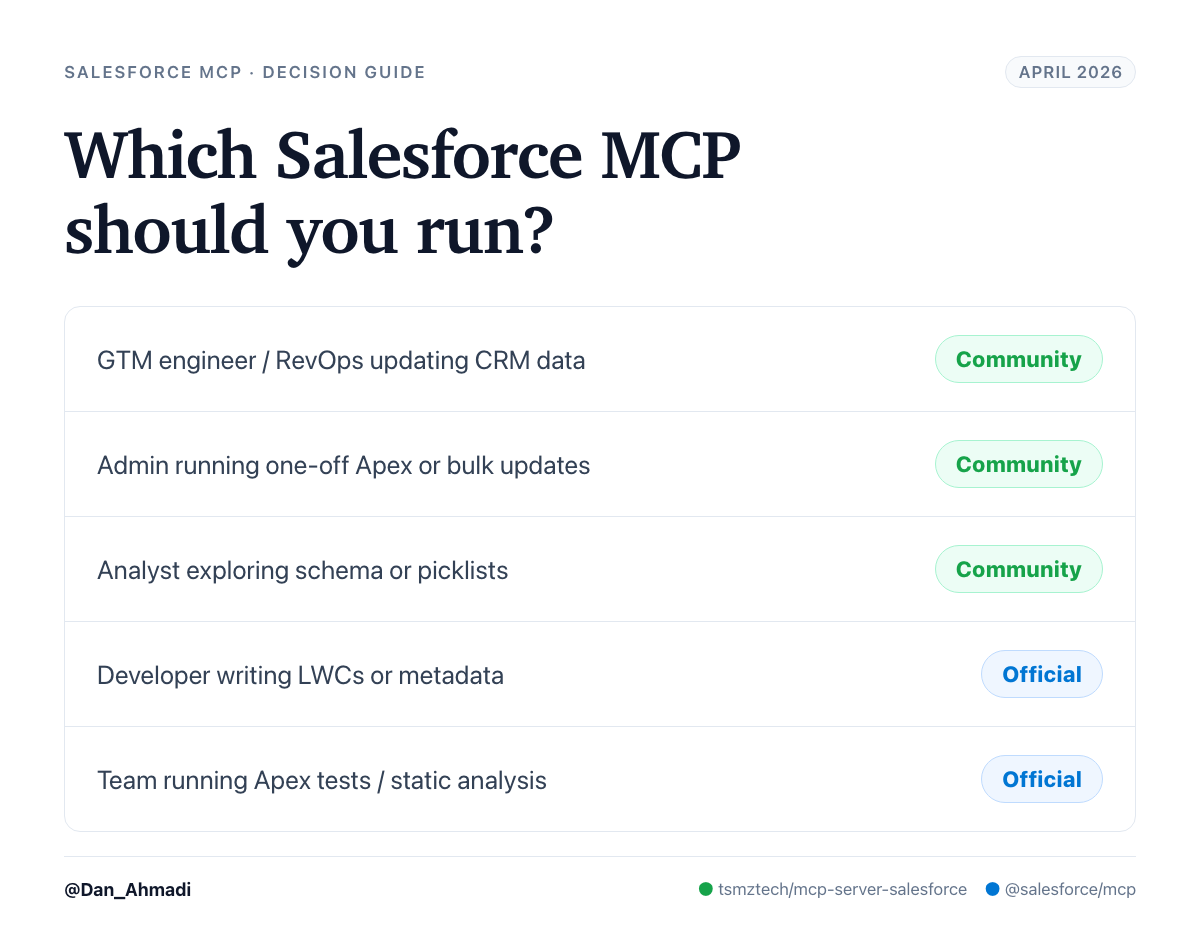
The bigger point: GTM engineers are builders. It’s hard to build if you can’t easily write.
My take
Salesforce doesn’t really want you to leave Salesforce. The Headless 360 announcement is, in part, a reaction to the fact that agents operating over APIs make the UI optional, which threatens the stickiest thing about the platform. Responding to that by opening up the API surface is the right instinct. It’s a good step.
But the product that shipped under the MCP banner is a dev tool. It’s aimed at people writing LWCs and deploying metadata from Cursor. It is not the product a GTM engineer, RevOps leader, or operator wants when they say “let my agent update Salesforce for me.”
The solo-maintained, 153-star community project is closer to what that pitch describes than the thing Salesforce shipped.
So for now: I’m still running the community MCP. It’s what turns “the best CRM is the one your team never has to open” from a tagline into a workflow. When Salesforce ships DML, describe, SOSL, and anonymous Apex in the official package (and I hope they do, because first-party support matters), I’ll reconsider. Until then, I’ll keep using my open source MCP.
And look– I might be wrong here. I invite you to challenge my stance/findings here. Everything is moving so quickly, and I know I still have a ton to learn here.